People who practice refactoring often turn to the Gilded Rose exercise, originally posted by Bobby Johnson and extended and elaborated by Emily Bache. The exercise can be approached in many different ways. I think that makes it especially useful for exploring alternative ways of dealing with existing code bases.
Several years ago, Arlo Belshee came up with an interesting way to address existing code that he calls read by refactoring. I will admit that I haven’t discussed this with him directly, nor have I attended his training on the subject. I’m basing this on my reading of the idea online and experimenting with the approach on my own. So, I might be missing key aspects of the idea. Please feel free to correct me if that’s the case.
If I understand the idea correctly, then it goes like this: Typical development tools today include (a) version control systems that lend themselves to quick, safe changes, and (b) integrated development environments or smart text editors that have built-in (or at least add-on) support for safe refactorings and code reformatting. The refactorings we’re most likely to use are those Arlo calls the “core 6” refactorings. These are pretty basic ones that most refactoring tools support.
That being the case, rather than just thinking about, talking about, and making notes about how to make the code more understandable, we can go ahead and refactor the code even while we’re reading it for the very first time. We can work quickly, thanks to the refactoring support offered by our IDE or editor, and we can revert the code at any time thanks to modern version control systems.
A complementary idea from Arlo is that coming up with good names for things like variables and methods is a process, and not a one-shot decision. In his series of articles on the subject, he points out that naming an element in a program is a design activity. When you imagine you’re just trying to think of a name, what’s going on in your mind may include as many as eight different design-related concepts. When you’re refactoring existing code while reading it for the first time, it’s very unlikely you will be able to think of good names for things immediately. So, he recommends gradually improving the names of things as you proceed with further refactoring and you learn more about what the code does and why.
Why Gilded Rose?
A few weeks ago a number of people were playing around with the Gilded Rose exercise in various ways, and it occurred to me it might be interesting to try the read by refactoring approach with that code. I didn’t get around to it until just now, despite the occasional friendly nudge.
Who says the code isn’t understandable?
Sometimes it seems as if software developers enjoy arguing more than they enjoy developing software. A recent argument has been about the idea of “clean code” or “habitable code.” If we propose to read by refactoring, who says the changes we’re making actually result in clearer code? One person might like a certain naming convention or code structure and the next person doesn’t. Are we really improving the code, or merely making it conform to our personal preferences?
For example, consider this article by Sam Hughes (if that’s the name; he/she does a good job of concealing the name on the site, so I’m not really sure) critiquing some of the advice given by Robert Martin in his book, Clean Code. Is a long, self-describing method name better than a short, cryptic one?
For what it’s worth, I think it comes down to avoiding extremes. The name smallestOddNthMultipleNotLessThanCandidate() is certainly self-descriptive, but it feels like reading a book. In contrast, a name like check() is nice and short, but doesn’t tell me much about what the code thinks it’s doing.
Maybe the trick isn’t to pick one or the other approach, but to think about balance and reasonableness. The problem is, the words “balance” and “reasonableness” are pretty subjective. One person’s “extreme” is another person’s “perfect.”
Another school of thought is emerging that questions the need to refactor code to the nth degree. I’ve lost track of the link to the talk on YouTube, but there’s a presentation that suggests the Japanese concept of wabi-sabi may be relevant to code bases. Sometimes, a bit of duplication actually makes the code easier to follow than it would be if we dogmatically made the code as DRY as possible. The “imperfections” in the code may, in some cases, reveal the intent of the code more clearly than a letter-perfect but sterile refactoring, in much the same way as the “imperfections” in raku pottery are a key element of its charm.
With all that in mind, it’s very possible this entire exercise is a waste of time. It’s just another programmer playing around with a code kata for his own amusement, and it has no practical value to anyone else. So be it.
Choice of tools
Arlo strongly recommends using an IDE that has good support for basic refactorings. We don’t want to spend time doing refactorings by hand or figuring out how we messed up a refactoring that we did by hand. We want to maintain fluidity of reading the code even as we apply small refactorings to it.
Two IDEs are especially recognized for their refactoring support: Microsoft VisualStudio and JetBrains IntelliJ IDEA. However, these IDEs do not handle all source languages equally well. VisualStudio’s refactoring support is best for C#, and IntelliJ’s is best for Java. Eclipse is another good choice for the Java language. While these IDEs can support editing of other languages, their refactoring support isn’t quite as strong for those languages. With those factors in mind, I decided to do this exercise in Java using IntelliJ IDEA.
You can set up your development environment in any way you please, but in case you’re curious here’s what I did: I set up an Ubuntu Linux VM under VMware Fusion on a MacBook pro laptop, and installed Gradle, Java 14 and IntelliJ IDEA Community Edition on it. I’m not reiterating the installation details here as that’s not really the topic of the post, and besides that you probably have your own way of setting up development tools.
Getting started
Quite deliberately, the starter code for the Gilded Rose kata doesn’t have any useful unit test cases. It’s possible to refactor without the “safety net” of executable tests, but most people prefer not to do that unless it’s unavoidable, as there’s a risk of changing behavior without noticing.
A popular way to get started is to use the so-called golden master approach. You run the code with a representative sample of input values and capture the output it generates. To check whether you’ve inadvertently changed the behavior of the code when refactoring, you run the code again with the same input values and see if it produces the same output as before. The captured results from the first run are the “golden master” against which you compare the results of subsequent runs.
I’m going to begin that way. At this point, we haven’t started the read by refactoring activity. We’re just getting a sample of the output produced by the existing code so we’ll have a way to ensure we haven’t changed its behavior unintentionally as we proceed.
I asked Emily Bache about the status of TextTest. She said it was still supported and still had an active user base, but the web site hasn’t been updated recently. Rather than take on another learning curve on top of read by refactoring, I thought it would be prudent to run the code and generate the “golden” output file. Subsequently, I can run refactored code and then diff the golden and test output files. Close enough for jazz.
First step is to grab the repo:
git clone https://github.com/emilybache/GildedRose-Refactoring-Kata
Next, I opened the project in IntelliJ IDEA and ran:
gradle test
just to be sure the single provided unit test failed for the right reason. The compile steps ran without error and the unit test failed as expected. That meant I had imported the project correctly.
There’s a test file under src/test/java to be used with TextTest, called TexttestFixture.java. It does not actually have a dependency on the TextTest tool. This class runs the Gilded Rose application, passing input data to it and executing through a specified number of days. Originally it specifies 2 days. I changed that to 30 and ran the class as a Java application from inside IntelliJ IDEA.
Apparently there’s no easy way to redirect stdout inside the IDE, so I cheated and copy/pasted the output from the run into a text file, which I named “golden.txt”.
Before doing any refactoring, I wanted to be sure a diff would provide useful information if any of the output didn’t match the “golden master” file. To check this without modifying the source code, I removed one of the items from the input data (hardcoded in TexttestFixture.java) and ran the program again. Cheating again to save the file with the new output, I then used IntelliJ’s built-in diff feature to compare the two files. This process appears to serve the purpose well enough for this exercise.
There’s something to keep in mind here, and I think it’s important when we’re working with existing code: We aren’t saying the test proves the code is “correct.” We’re only capturing its present behavior, whether right or wrong. We want to be sure the refactorings we apply will not change the existing behavior. We aren’t at the point of worrying about correctness just yet.
At that point I was ready to start reading by refactoring!
Code shape and seams
I think a couple of other ideas are useful for this exercise. One is the notion that source code has a shape that can offer a visual indication of where improvements might be possible. I learned this idea from the work of Sandi Metz. I don’t remember from which of her presentations I learned it, but I think this one mentions the idea: RailsConf 2014: All the Little Things. That presentation uses the same exercise as we’re using here, Gilded Rose, as the sample code.
The second useful idea is the notion of seams in the code. This comes from Michael Feathers’ book, Working Effectively With Legacy Code. He also mentions it in this talk: Working Effectively With Legacy Code. Seams are logical places in a chunk of monolithic code where we might separate the code into smaller chunks.
I think these two ideas can work hand in hand. By noticing the shape of the code, we can often zero in on where the natural seams are. For instance, the Gilded Rose starter code has a zig-zag shape. It comprises a series of if/else blocks, which are indented in and out, in and out, forming a zig-zag pattern. Each if or else statement is potentially a logical place to tease the code apart – a seam. I say “potentially” because we still have to read the code and get a sense of what it’s doing so we can decide whether and how to refactor it. We normally use the Extract Method refactoring quite a lot with code that has this shape.
These ideas are helpful when reading unfamiliar code, but they aren’t rigid rules. I’ve played with this code before, so I know some variables are checked in multiple places in the code. I’m trying hard to pretend I don’t know that yet, but it’s difficult. Anyway, it means just pulling the lines from an else block into a separate method won’t entirely do the job. Further refactoring will be needed to clarify the code.
Pay no attention to the goblin in the corner
Bobby Johnson’s original write-up for the exercise includes the warning: “…do not alter the Item class or Items property as those belong to the goblin in the corner who will insta-rage and one-shot you as he doesn’t believe in shared code ownership..”
That’s as may be, but we’re entering a brave new world of refactoring freely while reading unfamiliar code for the first time. If we think the Item class needs to be modified, we’ll modify it without asking anyone’s permission. The goblin in the corner will just have to get used to it.
Granted, this would make the exercise much easier if we were following the original instructions. We’re going to pretend we don’t know that yet, so we can try out the read by refactoring approach.
First impressions
Quickly scanning the code, it looks as if the updateQuality() method adjusts the “quality” attribute of each item for a single day, depending on certain characteristics of each item. Item characteristics are not encapsulated in the Item class. No doubt that’s why the goblin wants us to leave that class alone; otherwise, there would be no need for most of the conditional logic. But let’s see what we can do with the code without touching the Item class, just for fun.
Reduce clutter a little bit
The first thing that jumps out at me is all these references to items[i]. This may not be the sort of refactoring Arlo has in mind, but I’d like to reduce that clutter, even if only by a little. Where we have this sort of thing:
for (int i = 0; i < items.length; i++) {
if (!items[i].name.equals("Aged Brie")
…I’d rather see this sort of thing:
for (Item item : items) {
if (!item.name.equals("Aged Brie")
I know it isn’t much of a change, but it reduces visual clutter a little bit. Reducing visual clutter is a good thing, as it becomes easier to see what the code is trying to say.
<digression>
Edit: My original statement here is wrong:
But this isn’t a formal refactoring with a special name and a menu item in the IDE. It’s just a find-and-replace edit. That’s okay. It’s still a change to the structure of the code that doesn’t change the behavior of the code.
This isn’t exactly Arlo’s thing, as I didn’t (and couldln’t) use the IDE’s refactoring support to make this sort of change. I manually changed the for statement and then used IntelliJ’s search-and-replace feature to change all occurrences of items[i] to item.
Correction: Emily Bache let me know there’s a built-in refactoring to do this in IntelliJ IDEA – it’s Extract Variable. I didn’t know that refactoring at the time I wrote this post. Check out Emily’s article and video for more information about this refactoring: Advanced Testing and Refactoring Techniques.
</digression>
Before doing anything else, I ran the program to generate the output again, and used IntelliJ’s diff feature to compare the result to the golden.txt file. The result: “Contents are identical.” So far, so good!
Extract “degrade” and “enhance” methods
It appears the updateQuality() method modifies an item’s quality by one; all references either add one or subtract one. So I’m going to extract a method to decrement the quality and call it degrade().
I highlighted the first occurrence of item.quality – 1; and pressed ctrl+alt+M, the keyboard shortcut for Extract Method in IntelliJ IDEA. The IDE suggested the following:
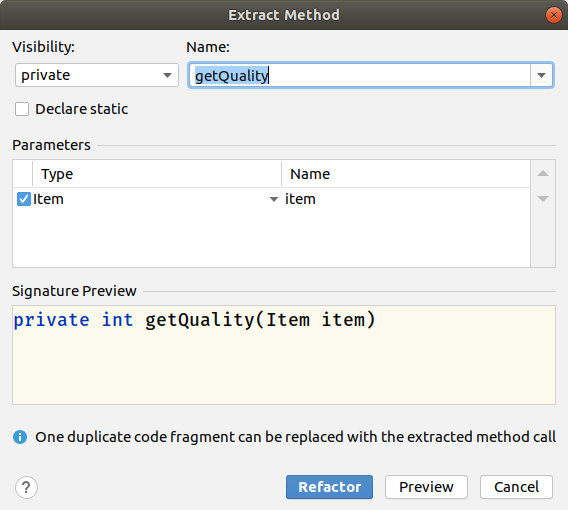
The preview of the method looked like this:
private int getQuality(int quality, int i) {
return quality - i;
}
That’s not even close to what I had in mind. I tried highlighting item.quality = item.quality -1;. The IDE suggested the following:
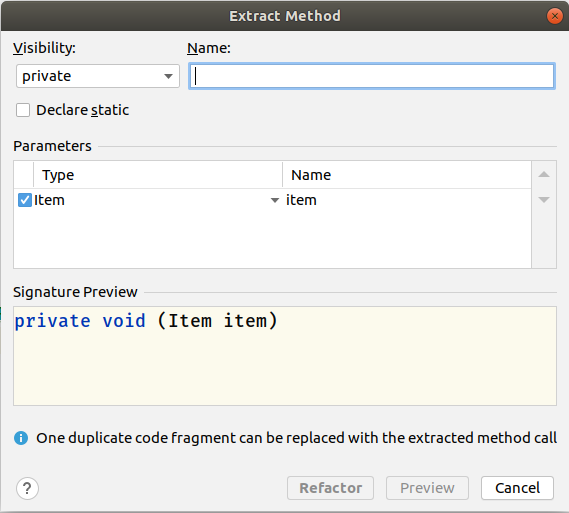
I typed in degrade as the method name, and the preview of the method looked like this:
private void degrade(Item item, int i) {
item.quality = item.quality - i;
}
I liked that better, but I want the method to return an Item rather than updating the item as a hidden side-effect. I’d also like Item to be immutable. (Is that more than we should be doing at this point, per Arlo’s approach? I’m not sure.) In any case, the IDE can’t handle that in a quick and easy way. I decided to go with the IDE’s suggestion, just to keep the exercise moving forward. The IDE changed two occurrences. Where the original code was:
if (!item.name.equals("Sulfuras, Hand of Ragnaros")) {
item.quality = item.quality - 1;
}
the code became:
if (!item.name.equals("Sulfuras, Hand of Ragnaros")) {
degrade(item);
}
It looks a little less cluttered, even if I’m not particularly happy with it. Next, I did the same for for cases when the quality is incremented. Where the code looked like this:
if (item.quality < 50) {
item.quality = item.quality + 1;
we now had:
if (item.quality < 50) {
enhance(item);
After running it again, the diff shows we still have identical content; we haven’t changed the behavior of the original code.
About Naming as a Process
The names degrade and enhance are likely to be more meaningful than Arlo’s canonical first step, “Get to Obvious Nonsense.” The word quality is a clue – if you increase quality, that’s an enhancement; if you decrease quality, it’s a degradation. If the code proves to mean something very different from this, then we can change it when we learn more about it. For now, I think it’s a reasonable choice of names for these methods.
As I said, I’m not an expert in this approach, but it seems reasonable that we needn’t follow each step in the naming process by rote every single time. We can use common sense.
Extract constants for minimum and maximum quality values
The code contains numeric literals that appear to represent the floor and ceiling values for item quality. My next step was to pull those out into constants, still inside the same class.
I used Extract Constant (ctrl+alt+C in this IDE) and checked the box for “Replace all occurrences,” changing the literal 0 to MINIMUM_QUALITY and the literal 50 to MAXIMUM_QUALITY. For instance:
if (item.quality > 0) {
became
if (item.quality > MINIMUM_QUALITY) {
There was one occurrence of a literal 0 that was not decrementing quality:
if (item.sellIn < 0) {
I had to be careful not to include that one in the Extract Method refactoring.
The output still matched the “golden” version.
Extract constants for item names
In the meantime, there are more cosmetic improvements we can make as we try to make the code more understandable. An obvious one is that item names are hard-coded in multiple places in method updateQuality. Let’s extract constants for those. Doing so might make it more obvious how to start pulling logic out of GildedRose and into specific Item classes, too.
So, this sort of code…
if (!item.name.equals("Aged Brie")
&& !item.name.equals("Backstage passes to a TAFKAL80ETC concert")) {
if (item.quality > MINIMUM_QUALITY) {
if (!item.name.equals("Sulfuras, Hand of Ragnaros")) {
degrade(item);
…becomes this sort of code:
if (!item.name.equals(AGED_BRIE)
&& !item.name.equals(BACKSTAGE_PASSES)) {
if (item.quality > MINIMUM_QUALITY) {
if (!item.name.equals(SULFURAS)) {
degrade(item);
Impressions so far
Up to this point, I’m not too impressed. Read by refactoring feels like normal refactoring to me. I must be doing something differently than Arlo does. If this technique has a special name and articles written about it and training classes to teach it, there must be more to it than this.
Next steps
The changes have been somewhat positive, but not significant. The structure of the GildedRose class is still the same as it was originally. We’ve only made a few very basic cosmetic improvements.
I’m visualizing moving a lot of the logic into Item, and making specific Item classes for each type of item. That may or may not appeal to everyone. The goblin, for one, will not like it. But it seems as if the rules for updating the quality of each item would be clearer if they were encapsulated in specific Item classes. I could be wrong.
What do we have here? There are various types of items. Each begins life with a certain value for “quality.” Day by day, the quality changes according to a few rules. Most items follow the same rules. Three special types of items have slightly different rules.
It seems reasonable to me that the Item class should “know” the rules for changing the quality of an item. Special categories of items can be defined as subclasses so they can override the default rules.
What about the goblin? He needs to get his head out of the Industrial Age and embrace the idea of collective code ownership.
Moving default logic to Item
So, I want to do a multi-step refactoring to move the default “update quality” logic out of GildedRose and into Item.
First, the constants can’t stay in GildedRose. They will have to be accessible from multiple classes. So, I extract them to an interface called Constants and have GildedRose and Item both implement that interface.
package com.gildedrose;
public interface Constants {
int MINIMUM_QUALITY = 0;
int MAXIMUM_QUALITY = 50;
String AGED_BRIE = "Aged Brie";
String BACKSTAGE_PASSES = "Backstage passes to a TAFKAL80ETC concert";
String SULFURAS = "Sulfuras, Hand of Ragnaros";
}
class GildedRose implements Constants {
. . .
class Item implements Constants {
. . .
Another stylistic choice is not to implement the Constants interface, but to code qualified references to the constant names. This makes client code a little less concise, but also makes it very clear where each constant is defined. It’s a judgment call.
Running the code and diffing the golden and new results files, we find we haven’t changed behavior. OK so far.
Now we want the enhance and degrade methods to be in the Item class. For my first small step, I’m going to copy those methods, not move them. The existing updateQuality method in class GildedRose has to continue to work for all items while we start to shift that functionality into Item.
Now we’re introducing new code, so I want to test-drive it. I’ll start by writing a microtest for Item.enhance().
package com.gildedrose;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.assertEquals;
class ItemTest {
@Test
void enhanceIncreasesItemQualityByOne() {
Item item = new Item("TestItem", 5, 3);
item.enhance();
assertEquals(4, item.quality);
}
}
There’s the usual TDD rigamarole – no such method as “enhance,” etc. We’ll just speed through all that, as it isn’t the purpose of this post to explain TDD. Then we do the same for the degrade method.
Should have noticed before, but didn’t: Every time enhance is called, the client code checks whether the quality is already at maximum. I want to bake that into the new enhance method. That means more microtests to drive out the functionality. I ended up with this:
package com.gildedrose;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.assertEquals;
class ItemTest implements Constants {
@Test
void whenItemQualityIsBelowMaximum_enhanceIncreasesItemQualityByOne() {
Item item = new Item("TestItem", 5, 3);
item.enhance();
assertEquals(4, item.quality);
}
@Test
void whenItemQualityIsAtMaximum_enhanceDoesNotChangeQuality() {
Item item = new Item("TestItem", 5, MAXIMUM_QUALITY);
item.enhance();
assertEquals(MAXIMUM_QUALITY, item.quality);
}
@Test
void degradeReducesQualityByOne() {
Item item = new Item("TestItem", 5, 6);
item.degrade();
assertEquals(5, item.quality);
}
}
public class Item implements Constants {
. . .
protected void enhance() {
if (quality < MAXIMUM_QUALITY) {
quality = quality += 1;
}
}
protected void degrade() {
quality -= 1;
}
. . .
The microtests seem to be okay for now. Running the program again and diffing again, it looks as if we haven’t changed any behavior inadvertently.
I feel as if there’s risk of breaking the code at this point, so I’m going to move slowly. I want to find one spot in GildedRose.updateQuality() that performs a “default” change to item quality, and change only that one occurrence to use one of the new methods in Item. This looks like a candidate:
if (!item.name.equals(AGED_BRIE)
&& !item.name.equals(BACKSTAGE_PASSES)) {
if (item.quality > MINIMUM_QUALITY) {
if (!item.name.equals(SULFURAS)) {
// this only happens for items other than the "special" ones:
degrade(item);
}
. . .
if (!item.name.equals(AGED_BRIE)
&& !item.name.equals(BACKSTAGE_PASSES)) {
if (item.quality > MINIMUM_QUALITY) {
if (!item.name.equals(SULFURAS)) {
// made just this change:
item.degrade();
}
. . .
After running the program and diffing the result files, this appears to have been a safe change. Now to look for other “default” behaviors in GildedRose.updateQuality() and make similar changes.
A little further down in the same if/else structure we have some interesting logic:
. . .
if (item.quality < MAXIMUM_QUALITY) { <= default behavior
enhance(item); <= default behavior
if (item.name.equals(BACKSTAGE_PASSES)) { <= backstage pass only
if (item.sellIn < 11) {
if (item.quality < MAXIMUM_QUALITY) {
enhance(item);
}
}
if (item.sellIn < 6) {
if (item.quality < MAXIMUM_QUALITY) {
enhance(item);
}
}
}
. . .
The code is a bit tricky to read, but I think that first enhance call applies to the default case. I’m going to make just the one change and see what happens. We don’t want to change the enhance calls for backstage pass items, as we don’t yet have a custom class for that type of item.
. . .
item.enhance();
if (item.name.equals(BACKSTAGE_PASSES)) {
if (item.sellIn < 11) {
if (item.quality < MAXIMUM_QUALITY) {
enhance(item);
}
}
if (item.sellIn < 6) {
if (item.quality < MAXIMUM_QUALITY) {
enhance(item);
}
}
}
. . .
My expectation is that I haven’t affected any logic pertaining to “Aged Brie” or “Sulfuras,” and the change I made will apply to “Backstage Passes” and all “normal” items. I’m nervous because the change involved removing a level of indentation in the if/else structure, and in my experience that’s a situation when I tend to make mistakes.
Whew! It’s okay so far. The new output file and the “golden” file are still identical.
There’s one more interesting chunk of code. If I’m reading the logic correctly, it falls out this way:
. . .
if (item.sellIn < 0) {
if (!item.name.equals(AGED_BRIE)) {
if (!item.name.equals(BACKSTAGE_PASSES)) {
if (item.quality > MINIMUM_QUALITY) {
if (!item.name.equals(SULFURAS)) {
degrade(item); <= default behavior
}
}
} else {
item.quality = item.quality - item.quality; <= Backstage Passes only
}
} else {
if (item.quality < MAXIMUM_QUALITY) { <= Aged Brie only
enhance(item);
}
}
}
. . .
Continuing with my careful strategy, I’m going to change just the one line labeled “default behavior” above.
. . .
if (item.sellIn < 0) {
if (!item.name.equals(AGED_BRIE)) {
if (!item.name.equals(BACKSTAGE_PASSES)) {
if (item.quality > MINIMUM_QUALITY) {
if (!item.name.equals(SULFURAS)) {
item.degrade(); <= the only change
}
}
} else {
item.quality = item.quality - item.quality;
}
} else {
if (item.quality < MAXIMUM_QUALITY) {
enhance(item);
}
}
}
. . .
Okay, still good. At least, still no evidence that we’ve changed the behavior of the application, based on diffing the latest test results file and the “golden” results file.
Custom logic for “Aged Brie”
If I’m reading this correctly, then there’s very little in the first big if/else structure that pertains to “Aged Brie,” and that very little thing is already handled by the default logic:
. . .
if (!item.name.equals(AGED_BRIE)
&& !item.name.equals(BACKSTAGE_PASSES)) {
if (item.quality > MINIMUM_QUALITY) {
if (!item.name.equals(SULFURAS)) {
item.degrade();
}
}
} else {
item.enhance(); <= only thing affecting Aged Brie
if (item.name.equals(BACKSTAGE_PASSES)) {
if (item.sellIn < 11) {
if (item.quality < MAXIMUM_QUALITY) {
enhance(item);
}
}
if (item.sellIn < 6) {
if (item.quality < MAXIMUM_QUALITY) {
enhance(item);
}
}
}
}
. . .
So, there’s nothing to do for “Aged Brie” there. Let’s look at the next big if/else structure.
. . .
if (item.sellIn < 0) {
if (!item.name.equals(AGED_BRIE)) {
if (!item.name.equals(BACKSTAGE_PASSES)) {
if (item.quality > MINIMUM_QUALITY) {
if (!item.name.equals(SULFURAS)) {
item.degrade();
}
}
} else {
item.quality = item.quality - item.quality;
}
} else { <= applies only to Aged Brie
if (item.quality < MAXIMUM_QUALITY) {
enhance(item);
}
}
}
. . .
This code does contain some logic that pertains exclusively to “Aged Brie.” Apparently it continues to increase in quality even after the “sell in” time period has passed. The simplest change here is to call the enhance method in the Item class; we don’t need to override it for “Aged Brie.”
This may change going forward. I can see the possibility of eliminating this if/else block altogether, or at least simplifying it considerably. I can see moving the check for sellIn into the Item class or its subclasses. At that time, we may need a little bit of custom logic for “Aged Brie.” For now, I don’t think we need an AgedBrie class. Let’s try it that way and see if the default logic already handles this case.
. . .
if (item.sellIn < 0) {
if (!item.name.equals(AGED_BRIE)) {
if (!item.name.equals(BACKSTAGE_PASSES)) {
if (item.quality > MINIMUM_QUALITY) {
if (!item.name.equals(SULFURAS)) {
item.degrade();
}
}
} else {
item.quality = item.quality - item.quality;
}
} else { <= changed enhance() call
item.enhance();
}
}
. . .
Running the program and diffing again, we see we haven’t changed the behavior of the code. Good.
Custom logic for “Backstage Passes”
Let’s scan through the code in GildedRose.updateQuality() again, this time looking for special handling of “Backstage Pass” items.
The first big if/else block contains special logic for “Backstage Passes”:
. . .
} else {
item.enhance();
if (item.name.equals(BACKSTAGE_PASSES)) {
if (item.sellIn < 11) {
if (item.quality < MAXIMUM_QUALITY) {
enhance(item);
}
}
if (item.sellIn < 6) {
if (item.quality < MAXIMUM_QUALITY) {
enhance(item);
}
}
}
}
. . .
The degree of quality enhancement varies depending on how close we get to the sellIn day. It makes sense (to me) to encapsulate this in a custom Item subclass for this type of item.
Here’s what I came up with initially. Of course, we’re introducing new code again, so again we will test-drive it.
. . .
@ParameterizedTest
@MethodSource("provideSellInValues")
void forBackstagePasses_qualityIncreasesMoreAsSellInDateApproaches(
int sellInValue, int initialQuality, int expectedQuality) {
Item item = new BackstagePasses("TestItem", sellInValue, initialQuality);
item.enhance();
assertEquals(expectedQuality, item.quality);
}
private static Stream<Arguments> provideSellInValues() {
return Stream.of(
Arguments.of(1, 5, 8),
Arguments.of(5, 5, 8),
Arguments.of(6, 5, 7),
Arguments.of(10, 5, 7),
Arguments.of(11, 5, 6)
);
}
. . .
To make the microtests pass, I copied the logic from GildedRose.updateQuality() to a new class, BackstagePasses.
package com.gildedrose;
public class BackstagePasses extends Item {
public BackstagePasses(String name, int sellIn, int quality) {
super(name, sellIn, quality);
}
@Override
protected void enhance() {
quality += 1;
if (sellIn < 11) {
quality += 1;
}
if (sellIn < 6) {
quality += 1;
}
}
}
Now, to make the approval test pass, we need to remove that logic from GildedRose.updateQuality(). The code shown above becomes:
. . .
} else {
item.enhance();
}
. . .
One more change before we can run the approval test: In class TextestFixture we must instantiate BackstagePasses objects instead of Item objects:
. . .
Item[] items = new Item[] {
new Item("+5 Dexterity Vest", 10, 20), //
new Item("Aged Brie", 2, 0), //
new Item("Elixir of the Mongoose", 5, 7), //
new Item("Sulfuras, Hand of Ragnaros", 0, 80), //
new Item("Sulfuras, Hand of Ragnaros", -1, 80),
new BackstagePasses("Backstage passes to a TAFKAL80ETC concert", 15, 20),
new BackstagePasses("Backstage passes to a TAFKAL80ETC concert", 10, 49),
new BackstagePasses("Backstage passes to a TAFKAL80ETC concert", 5, 49),
// this conjured item does not work properly yet
new Item("Conjured Mana Cake", 3, 6) };
. . .
This time, the new output file did not match the “golden” output file that was generated from the original code. Of the three “Backstage Passes” items in TexttestFixture, the first one worked but the other two did not. After some investigation, I realized the original “golden” output file was wrong. The modified logic appeared to be doing what the specification called for. This seems strange, as I had taken some care not to alter the logic, but only to move it into the new class, BackstagePasses.
Rather than backtracking to figure out why the original output was wrong, I decided to plow ahead because the new logic appears to be correct. I’ve already deviated from both the read by refactoring exercise and the basic Gilded Rose refactoring kata, so this little experiment probably can’t be rescued. I decided to go ahead and finish the refactoring I had started, and call it a day.
The second big if/else block contains some logic unique to BackstagePasses. It looks like this:
. . .
if (item.sellIn < 0) {
if (!item.name.equals(AGED_BRIE)) {
if (!item.name.equals(BACKSTAGE_PASSES)) {
if (item.quality > MINIMUM_QUALITY) {
if (!item.name.equals(SULFURAS)) {
item.degrade();
}
}
} else {
item.quality = item.quality - item.quality; <= this applies to Backstage Passes
}
} else {
item.enhance();
}
}
. . .
It occurred to me the decrement of sellIn can be moved into the Item class. For the BackstagePasses subclass, the overridden method can zero out the quality at the appropriate time. We should also be sure BackstagePasses doesn’t try to enhance quality after the sellIn date has passed.
I started by adding microtest cases for BackstagePasses.enhance() that ensure the code does not enhance quality when sellIn is less than zero. I added this to the provideSellInValues() method in ItemTest:
. . .
Arguments.of(-1, 50, 0)
. .
That means when sellIn is -1 and quality is 50, we expect the resulting quality to be zero. This microtest case failed on the first try. I modified the logic in BackstagePasses.enhance() as follows:
. . .
@Override
protected void enhance() {
if (sellIn < 0) {
quality = 0;
} else {
quality += 1;
if (sellIn < 11) {
quality += 1;
}
if (sellIn < 6) {
quality += 1;
}
}
}
. . .
As I no longer trusted the “golden” output file, I just eyeballed the output from TexttestFixture. It looked as if BackstagePasses was being handled as expected.
Custom logic for “Sulfuras”
In between the two big if/else blocks in GildedRose.updateQuality(), there’s a smaller conditional snippet:
. . .
if (!item.name.equals(SULFURAS)) {
item.sellIn = item.sellIn - 1;
}
. . .
According to the specification, Sulfuras is a “legendary item,” which means its value is always 80 and it has no sellIn period. That can be baked into a custom subclass to simplify the client code in GildedRose.updateQuality().
A test case to drive the decrementSellIn() method in Item:
@Test
void decrementSellIn_reducedSellInValueBy1() {
Item item = new Item("TestItem", 4, 40);
item.decrementSellIn();
assertEquals(3, item.sellIn);
}
The default implementation of decrementSellIn() in Item:
. . .
protected void decrementSellIn() {
sellIn -= 1;
}
. . .
Test cases to drive custom logic in Sulfuras:
@Test
void sulfurasQualityDoesNotIncrease() {
Sulfuras item = new Sulfuras("TestItem", 5, 80);
item.enhance();
assertEquals(80, item.quality);
}
@Test
void sulfurasQualityDoesNotDegrade() {
Sulfuras item = new Sulfuras("TestItem", 5, 80);
item.degrade();
assertEquals(80, item.quality);
}
@Test
void sulfurasSellInDoesNotChange() {
Sulfuras item = new Sulfuras("TestItem", 5, 80);
item.decrementSellIn();
assertEquals(5, item.sellIn);
}
Custom subclass for Sulfuras:
package com.gildedrose;
public class Sulfuras extends Item {
public Sulfuras(String name, int sellIn, int quality) {
super(name, sellIn, quality);
}
@Override
protected void enhance() {}
@Override
protected void degrade() {}
@Override
protected void decrementSellIn() {}
}
This seems to “work,” but I’m not happy with it for a couple of reasons. For one thing, it doesn’t feel quite right for object oriented design. These three overrides remove functionality provided by the base class. This is not generally considered a good design practice.
For another, we have a class specific to Sulfuras, while the specification actually says the reason “Sulfuras” is treated this way is because it’s a “legendary” item. We probably need to have a category of items for “legendary” things. But we can follow Arlo’s naming process to improve the name if and when that becomes an issue.
We can simplify the logic in GildedRose.updateQuality() by replacing this:
. . .
if (!item.name.equals(SULFURAS)) {
item.sellIn = item.sellIn - 1;
}
. . .
to this:
. . .
item.decrementSellIn();
. . .
Further refactoring
There’s special handling for “Aged Brie” that we’ve been supporting via the existing code in GildedRose.updateQuality(). With the addition of method decrementSellIn() in the Item class, we have the opportunity to pull this small amount of special handling into a new subclass for AgedBrie items. “Aged Brie” continues to increase in quality even after the sell in period has passed. To handle that, I propose to add logic to the default enhance() method in Item to take no action when the sellIn value is less than zero, and to override this behavior in a custom AgedBrie subclass.
@Test
void agedBrieContinuesToImproveAfterTheSellInPeriod() {
AgedBrie item = new AgedBrie("TestItem", -1, 20);
item.enhance();
assertEquals(21, item.quality);
}
@Test
void standardItemsStopImprovingAfterTheSellInPeriod() {
Item item = new Item("TestItem", -1, 20);
item.enhance();
assertEquals(20, item.quality);
}
. . .
protected void enhance() {
if (sellIn > -1 && quality < MAXIMUM_QUALITY) {
quality = quality += 1;
}
}
. . .
package com.gildedrose;
public class AgedBrie extends Item {
public AgedBrie(String name, int sellIn, int quality) {
super(name, sellIn, quality);
}
@Override
protected void enhance() {
if (quality < MAXIMUM_QUALITY) {
quality = quality += 1;
}
}
}
With the microtests passing, I wanted to run the program again and check the overall output visually (don’t trust the “golden” file anymore). I ran it with the following items:
. . .
Item[] items = new Item[] {
new Item("+5 Dexterity Vest", 10, 20), //
new AgedBrie("Aged Brie", 2, 0), //
new Item("Elixir of the Mongoose", 5, 7), //
new Sulfuras("Sulfuras, Hand of Ragnaros", 0, 80), //
new Sulfuras("Sulfuras, Hand of Ragnaros", -1, 80),
new BackstagePasses("Backstage passes to a TAFKAL80ETC concert", 15, 20),
new BackstagePasses("Backstage passes to a TAFKAL80ETC concert", 10, 49),
new BackstagePasses("Backstage passes to a TAFKAL80ETC concert", 5, 49),
// this conjured item does not work properly yet
new Item("Conjured Mana Cake", 3, 6) };
. . .
AgedBrie appears to increase in quality at double the standard rate; not sure why, not going to worry about it just now.
At this point, I think it’s safe to remove all the following code from GildedRose.updateQuality():
. . .
if (item.sellIn < 0) {
if (!item.name.equals(AGED_BRIE)) {
if (!item.name.equals(BACKSTAGE_PASSES)) {
if (item.quality > MINIMUM_QUALITY) {
if (!item.name.equals(SULFURAS)) {
item.degrade();
}
}
} else {
item.quality = item.quality - item.quality;
}
} else {
item.enhance();
}
}
. . .
I removed that code and ran the program to generate another output file, then diffed that file with the most recent test run (not with “golden”).
In general the results aren’t too bad. AgedBrie is definitely behaving differently. I need to take a closer look at that. OK – found a fat-finger error:
@Override
protected void enhance() {
if (quality < MAXIMUM_QUALITY) {
quality = quality += 1;
}
}
This change fixed it:
@Override
protected void enhance() {
if (quality < MAXIMUM_QUALITY) {
quality += 1;
}
}
There’s still a chunk of code in GildedRose.updateQuality() I’d like to simplify, if possible.
. . .
if (!item.name.equals(AGED_BRIE)
&& !item.name.equals(BACKSTAGE_PASSES)) {
if (item.quality > MINIMUM_QUALITY) {
if (!item.name.equals(SULFURAS)) {
item.degrade();
}
}
} else {
item.enhance();
}
. . .
Given the refactorings we’ve done, I think it’s feasible to simplify that code. Let’s find out if that’s true.
package com.gildedrose;
class GildedRose implements Constants {
Item[] items;
public GildedRose(Item[] items) {
this.items = items;
}
public void updateQuality() {
for (Item item : items) {
switch (item.name) {
case AGED_BRIE:
case BACKSTAGE_PASSES:
item.enhance();
break;
default:
item.degrade();
}
item.decrementSellIn();
}
}
}
That code generates the same output as the previous version of the code.
I think I’ll go ahead and to a Rename refactoring from Sulfuras to Legendary. OK – tests still produce the same output.
Adding the conjured item
According to the specification, the difference between a “conjured” item and a standard item is that the “conjured” item degrades twice as fast as a standard item. That should be easy to implement in a Conjured subclass of Item, overriding the degrade() method.
@Test
void conjuredItemsDegradeAtTwiceTheRateOfStandardItems() {
Conjured item = new Conjured("Conjured Mana Cake", 5, 10);
item.degrade();
assertEquals(8, item.quality);
}
package com.gildedrose;
public class Conjured extends Item {
public Conjured(String name, int sellIn, int quality) {
super(name, sellIn, quality);
}
@Override
protected void degrade() {
if (quality > MINIMUM_QUALITY) {
quality -= 2;
}
}
}
I adjusted the expected results in my new “golden” output file based on the specification that conjured items degrade twice as fast as standard items. The new Conjured class appears to work as expected.
Conclusions
The code I wound up with is probably not the best possible implementation. And who knows if it’s really “correct” in the full sense of the word? It will have to do for now.
Regarding the read by refactoring approach, I’m at a loss to see what’s unusual, new, or special about it. I suspect I’m doing it all wrong, because given the thorough write-up and the fact there’s a training class on the subject suggest there’s more to it than just this. What I did just seems like normal work. In fact, I grew pretty bored with the whole exercise about midway through it. I had to force myself to reach a sensible place to end it.
One thing the exercise made clear – just as a thousand other similar experiences have done – is that taking a few minutes or even a few hours to do some refactoring of existing code before you try to add logic to it will save you a lot of time and stress; and you needn’t wait weeks or months to gain the benefits of the refactoring. You get the benefit the very first time you touch the code again. Note that after shuffling the code around for a couple of hours here, I was able to add the “conjured” item literally in a few seconds, including the microtests to test-drive it. I don’t know how long it would have taken otherwise.
All the links in one place
- Gilded Rose on Github: Bobby Johnson
- Gilded Rose on Github: Emily Bache
- Arlo Belshee’s article on the “core 6” refactorings
- Ken Richards’ article on Read by Refactoring
- Arlo Belshee’s article on Naming as a Process
- It’s probably time to stop recommending Clean Code: Sam Hughes
- Ron Jeffries’ blog posts on Gilded Rose
- RailsConf 2014: All the Little Things: Sandi Metz
- Working Effectively With Legacy Code: Michael Feathers